
Introduction
Data cleaning is the first step of data preprocessing, it consists in fixing or removing invalid and unwanted values from our dataset. Some common examples are:
- Duplicates
- Outliers
- Missing values
- Invalid formats
- Corrupted data
1. Dataset Analysis
First of all, what data do we have? Lets see what variables are present. This can be done importing the dataset into RapidMiner, adding the Retrieve operator, and connecting it to the output.
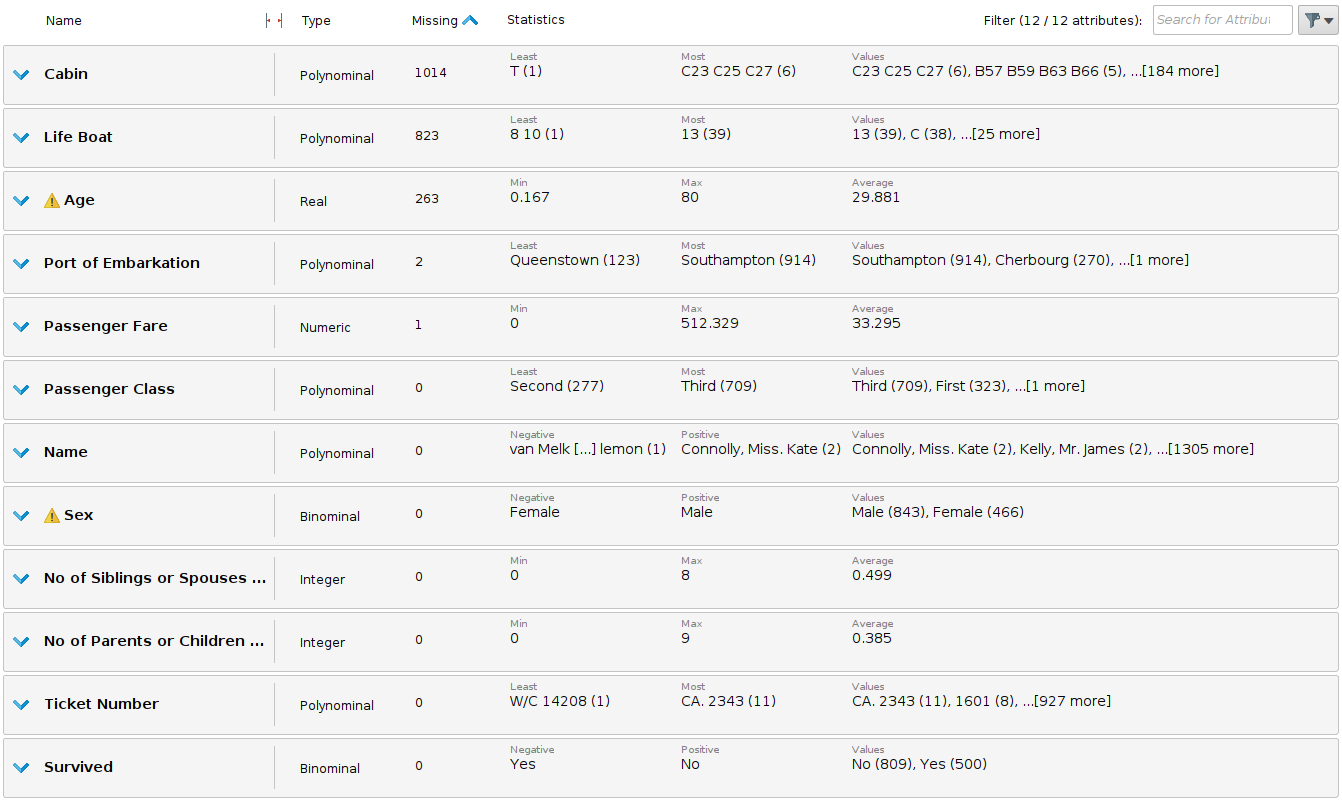
We have 1309 registers and 12 variables, where the target is Survived. At first glance we already see some problematic data, for example the amount of missing values.
2. Handling missing values
Some ML models, like Linear and Logistic Regression, do not support variables with missing values. In order to use them, this problem must be solved, and can be done with the following techniques:
2.1 Removing missing values
If a variable has few missing values consider deleting each of this rows, only if the dataset is big enough and you are sure that fewer examples will not be a problem. On the other hand, if more than 50% of a variable is missing, the best option to consider is droping the entire column.
For instance, more than half of the variables Cabin and Life Boat have missing values, so let's just remove them. Also, let's remove the 3 rows that have missing Port of Embarkation and Passenger Fare. In RapidMiner, add Select Attributes operator to include only selected variables, and Filter Examples operator to filter rows matching the given condition.
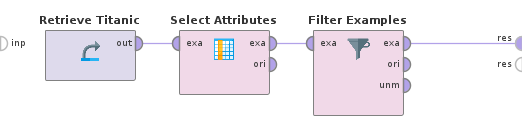
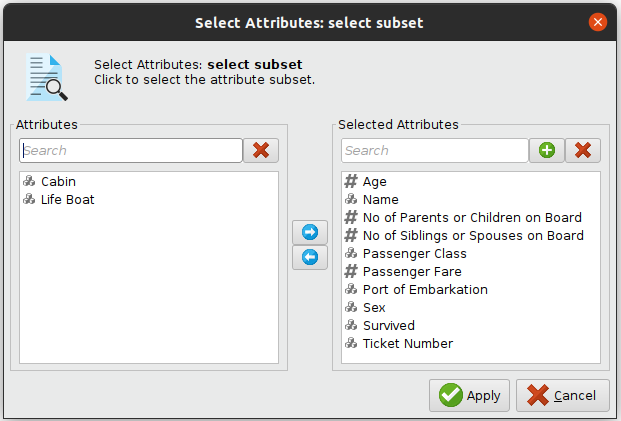
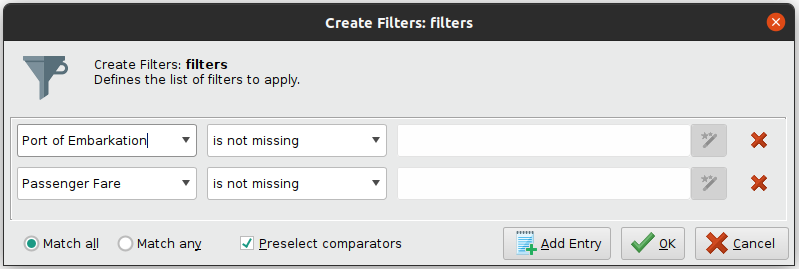
2.2 Impute artificial data
What about Age? Deleting 1/5 of the dataset (263 examples) may not be the best solution. Instead, we can impute numerical missing values with the mean of the variable. Although it's not a real value, it's an easy and useful fix for this case.
Add the Replace Missing Values operator and configure it in the following way:

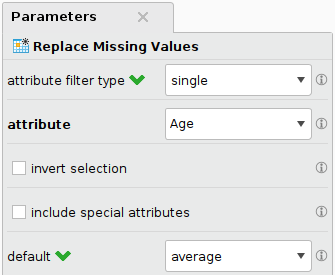
The variable distribution stays the same using the mean as value replacement. However, depending on the problem you can use other replacement values such as max, min, median or many others.
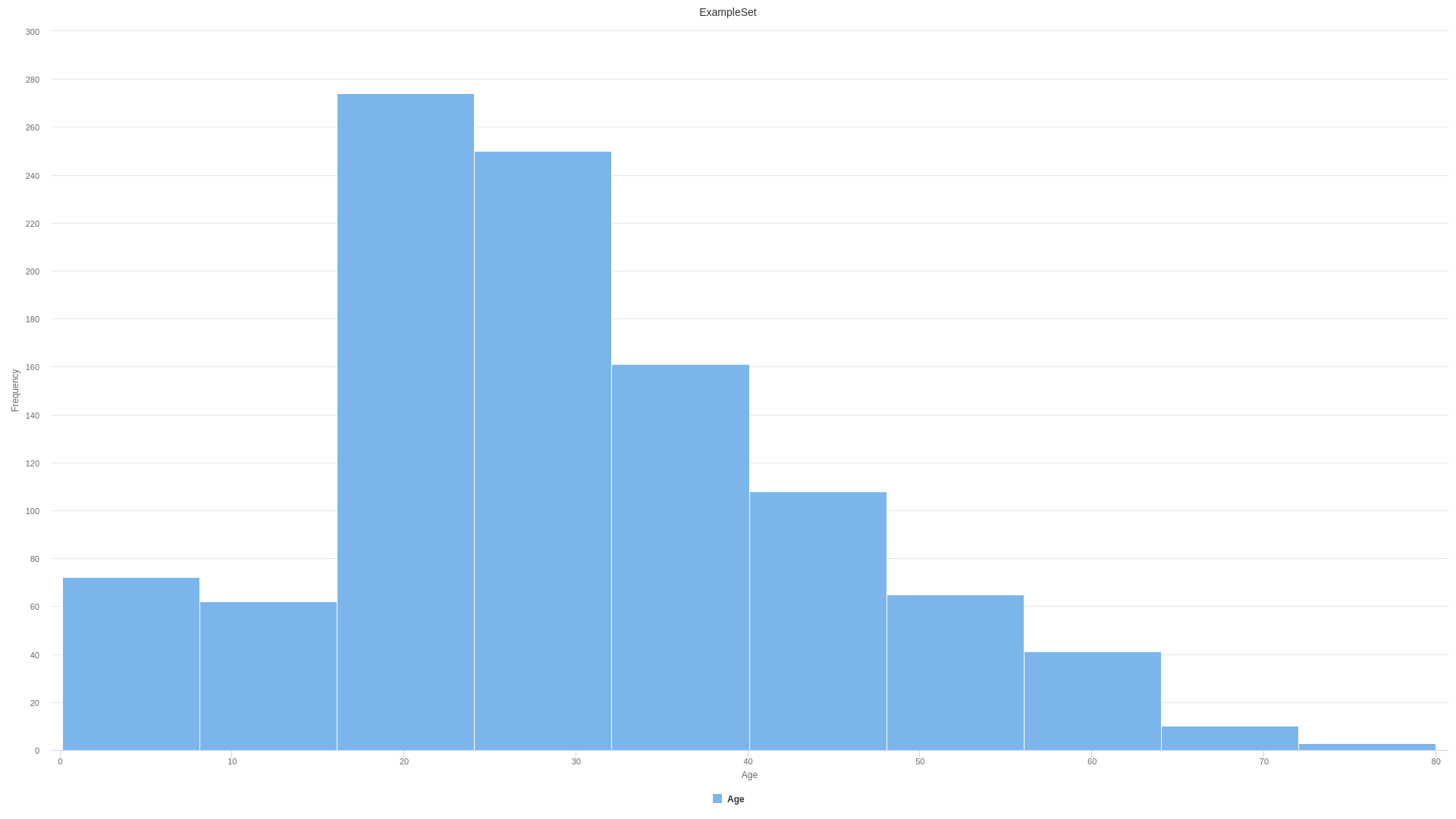
Age original distribution
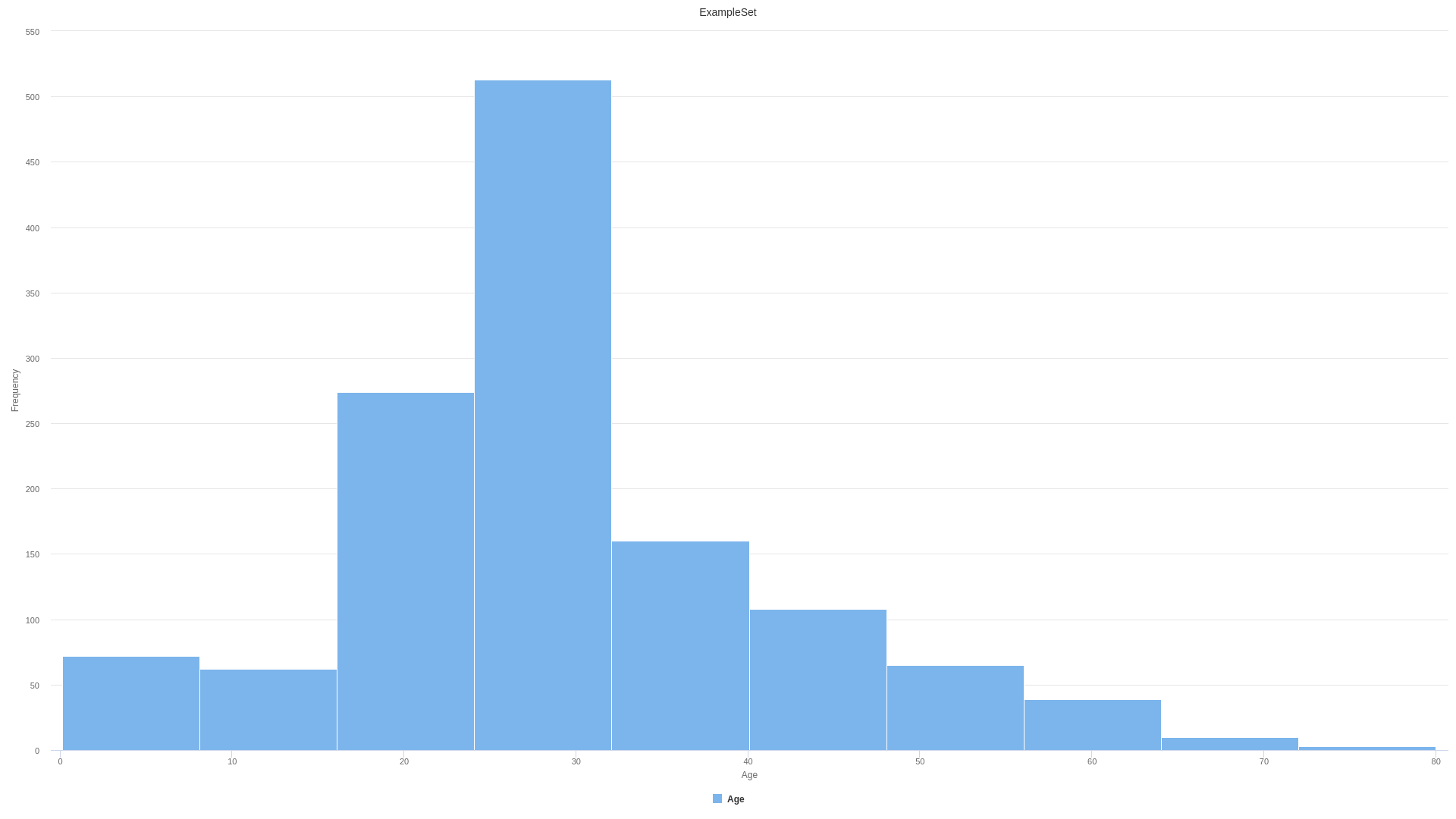
Age distribution after imputing with mean
3. Removing useless variables
Not all variables are useful for the model. Some are unrelated to the target variable, or too correlated. At first sight, the variables Name, Port of Embarkation, Ticket Number and Cabin will not change the fact if the passenger survived or not. On the other hand, the variable Life Boat is strongly correlated. To avoid making decisions based on this particular data, it is better to remove them using Select Attributes operator.
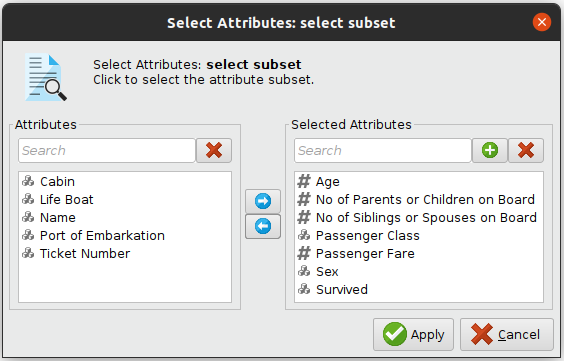
Further analysis may be done applying advanced feature selection techinques.
4. Removing Outliers
Outliers, which are abnormal values often introduced by errors, have an impact on data quality and models performance. For example, if we plot Passenger Fare distribution, it shows that few values are far separated from the others.
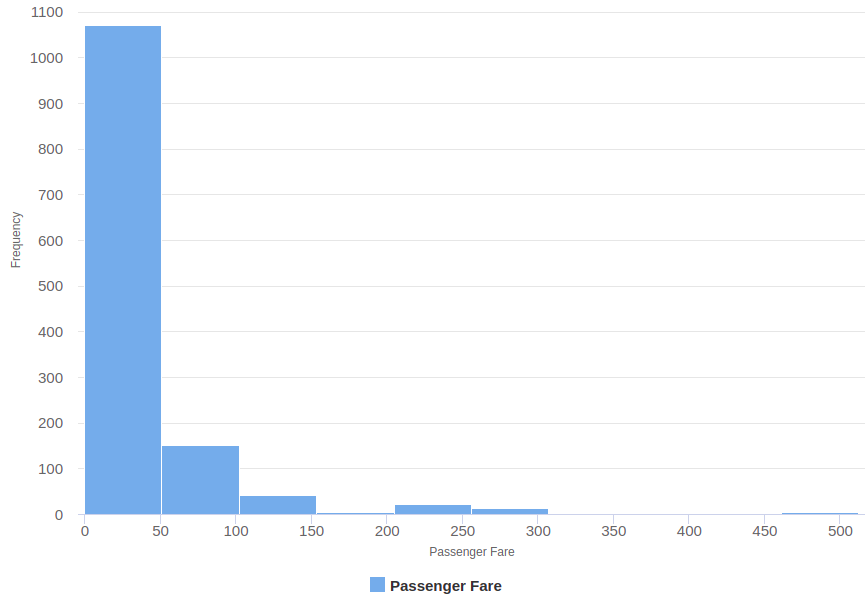
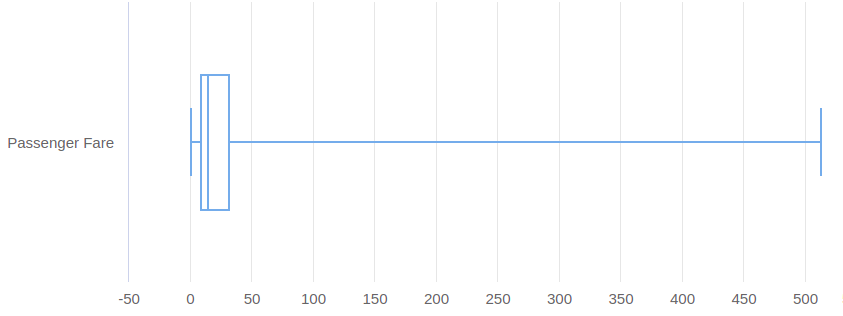
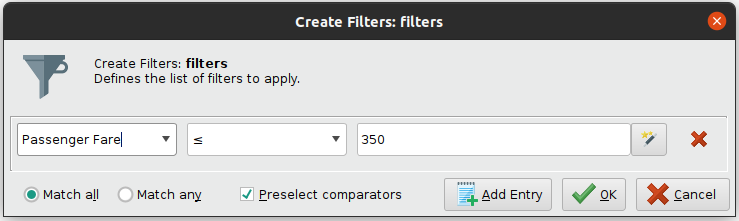
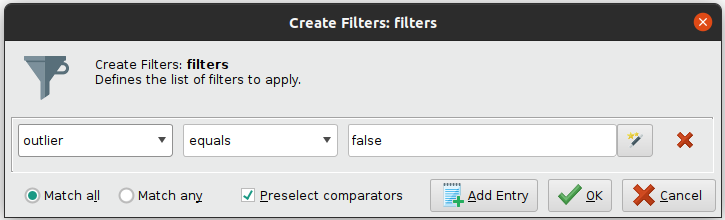
We should trim values above 350. Additionally, RapidMiner has a special operator for detecting outliers using distance based algorithms, which allow us to remove the top 10 outliers in the dataset. As we are working with distances, it is useful to normalize data, in this case using Z-Transformation.

Conclusion
At last, our dataset is clean and ready for the next step in data preprocessing: Transformations. However, there are many data cleaning techinques that did not apply to our dataset, but may be necesary in a different scenario. It is important to analyze if further improvements may be needed.
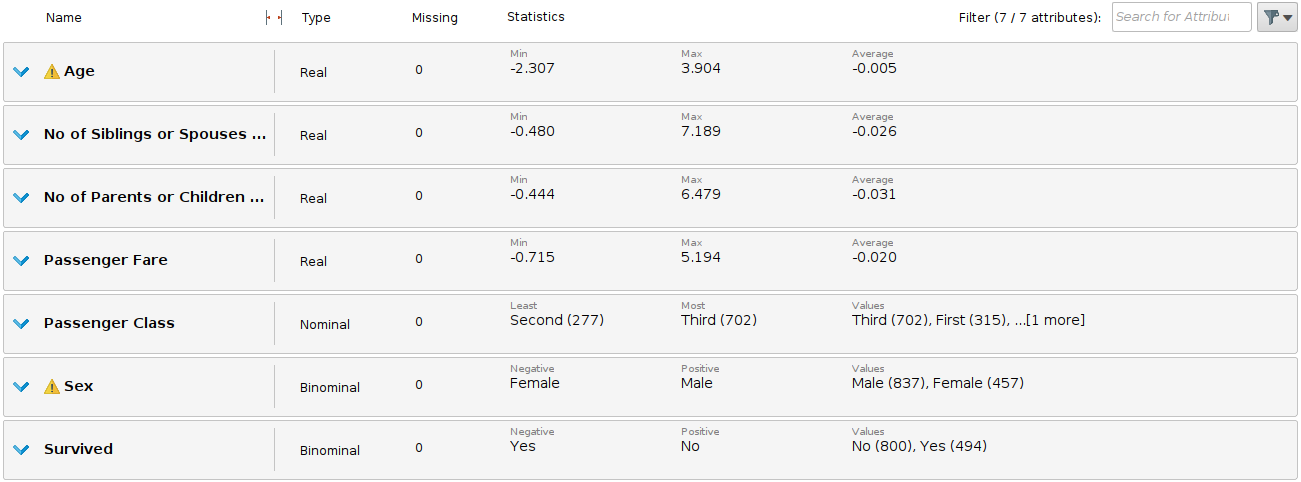 Final dataset with 1294 samples
Final dataset with 1294 samples
The complete RapidMiner process can be downloaded from here.